


Go back to Part 3: Steps to Calculate HV using MS Excel (with Example)
As Historical Volatility (HV) is calculated using standard deviation, it might be good to understand better about the concept of standard deviation, so that we can interpret the meaning of HV better.
Standard deviation is a measure of data variability or dispersion (i.e. how spread out the data points from its mean).
When the standard deviation is low, that means the data points tend to be very close to its mean (i.e. the data is spread out over a small range of values).
When the standard deviation is high, that means the data points tend to be far away from its mean (i.e. the data is spread out over a large range of values).
This can be understood from the formula below as well:

The numerator in the formula is the summation of the difference between individual data point and the mean of the data set.
If the data points tend to be very close to its mean (less spread out from the mean value), the difference between each individual data point and the mean would be relatively small, and hence the summation of all differences and, in turn, the standard deviation will be small too.
On the other hand, if the data points tend to be far away from its mean (more spread out from the mean value), the difference between each individual data point and the mean would be bigger, and hence the summation of all differences and, in turn, the standard deviation will be big too.
In denominator, “n – 1” is used instead of “n” to get an unbiased estimator, because this standard deviation is derived based on sample, not population. (If the population is used, then the dominator will be “n”).
Since the standard deviation is estimated based on sample, using “n – 1” as the denominator will “inflate” the standard deviation value to “capture more risks” due to estimating the standard deviation based on sample only instead of population. (Remember that to estimate HV, we’ll never be able to use “population”).
This adjustment is particularly essential when we estimate the standard deviation based on a small number of observations (i.e. when n is relatively small). However, when n is big, the difference between using “n – 1” or “n” is not very significant.
Standard Deviation of Normal Distribution
One important attribute of the standard deviation is that in a Normal Distribution, about 66.8% (two third) of the data are within one standard deviation of the mean, and about 95% of the data are within two standard deviations of the mean.
In Historical Volatility, price returns are assumed to be normally distributed, like shown in the picture below.

Source of picture: http://www.russell.com/us/glossary/analytics/standard_deviation.htm
Therefore, about two-third of the time, an individual return would fall within one standard deviation of the mean, and about 95% of the time, an individual return would fall within two standard deviation of the mean.
Continue to Part 5: How To Annualise Standard Deviation
To view the list of all the series on “Historical Volatility”, please refer to: “More Understanding about HISTORICAL VOLATILITY”
Other Learning Resources:
* FREE Trading Educational Videos with Special Feature
* FREE Trading Educational Videos from Trading Experts
Related Topics:
* Understanding Implied Volatility (IV)
* Understanding Option Greek
* Understanding Option’s Time Value
* Learning Candlestick Charts
* Options Trading Basic – Part 1
* Options Trading Basic – Part 2
As Historical Volatility (HV) is calculated using standard deviation, it might be good to understand better about the concept of standard deviation, so that we can interpret the meaning of HV better.
Standard deviation is a measure of data variability or dispersion (i.e. how spread out the data points from its mean).
When the standard deviation is low, that means the data points tend to be very close to its mean (i.e. the data is spread out over a small range of values).
When the standard deviation is high, that means the data points tend to be far away from its mean (i.e. the data is spread out over a large range of values).
This can be understood from the formula below as well:
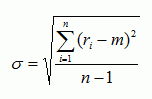
The numerator in the formula is the summation of the difference between individual data point and the mean of the data set.
If the data points tend to be very close to its mean (less spread out from the mean value), the difference between each individual data point and the mean would be relatively small, and hence the summation of all differences and, in turn, the standard deviation will be small too.
On the other hand, if the data points tend to be far away from its mean (more spread out from the mean value), the difference between each individual data point and the mean would be bigger, and hence the summation of all differences and, in turn, the standard deviation will be big too.
In denominator, “n – 1” is used instead of “n” to get an unbiased estimator, because this standard deviation is derived based on sample, not population. (If the population is used, then the dominator will be “n”).
Since the standard deviation is estimated based on sample, using “n – 1” as the denominator will “inflate” the standard deviation value to “capture more risks” due to estimating the standard deviation based on sample only instead of population. (Remember that to estimate HV, we’ll never be able to use “population”).
This adjustment is particularly essential when we estimate the standard deviation based on a small number of observations (i.e. when n is relatively small). However, when n is big, the difference between using “n – 1” or “n” is not very significant.
Standard Deviation of Normal Distribution
One important attribute of the standard deviation is that in a Normal Distribution, about 66.8% (two third) of the data are within one standard deviation of the mean, and about 95% of the data are within two standard deviations of the mean.
In Historical Volatility, price returns are assumed to be normally distributed, like shown in the picture below.

Source of picture: http://www.russell.com/us/glossary/analytics/standard_deviation.htm
Therefore, about two-third of the time, an individual return would fall within one standard deviation of the mean, and about 95% of the time, an individual return would fall within two standard deviation of the mean.
Continue to Part 5: How To Annualise Standard Deviation
To view the list of all the series on “Historical Volatility”, please refer to: “More Understanding about HISTORICAL VOLATILITY”
Other Learning Resources:
* FREE Trading Educational Videos with Special Feature
* FREE Trading Educational Videos from Trading Experts
Related Topics:
* Understanding Implied Volatility (IV)
* Understanding Option Greek
* Understanding Option’s Time Value
* Learning Candlestick Charts
* Options Trading Basic – Part 1
* Options Trading Basic – Part 2










